
Aurich Lawson | Imágenes Getty
El martes, investigadores de Google y la Universidad de Tel Aviv dieron a conocer JuegoNGenun nuevo modelo de IA que puede simular de forma interactiva el clásico juego de disparos en primera persona de 1993 Condenar en tiempo real utilizando técnicas de generación de imágenes de IA tomadas de Difusión estableEs un sistema de red neuronal que puede funcionar como un motor de juego limitado, abriendo potencialmente nuevas posibilidades para la síntesis de videojuegos en tiempo real en el futuro.
Por ejemplo, en lugar de dibujar cuadros de video gráficos utilizando técnicas tradicionales, los juegos futuros podrían potencialmente usar un motor de IA para “imaginar” o alucinar gráficos en tiempo real como una tarea de predicción.
““El potencial aquí es absurdo”, escribió El desarrollador de aplicaciones Nick Dobos reaccionó a la noticia: “¿Por qué escribir reglas complejas para un software a mano cuando la IA puede pensar cada píxel por ti?”
Según se informa, GameNGen puede generar nuevos cuadros de Condenar juego a más de 20 cuadros por segundo utilizando una sola unidad de procesamiento tensorial (TPU), un tipo de procesador especializado similar a una GPU que está optimizado para tareas de aprendizaje automático.
En las pruebas, los investigadores dicen que diez evaluadores humanos a veces no lograron distinguir entre clips cortos (1,6 segundos y 3,2 segundos) de contenido real. Condenar Imágenes de juego y resultados generados por GameNGen, identificando las imágenes de juego reales el 58 o 60 por ciento de las veces.
Un ejemplo de GameNGen en acción, simulando interactivamente Doom utilizando un modelo de síntesis de imágenes.
Síntesis de videojuegos en tiempo real utilizando lo que podría llamarse “representación neuronal“No es una idea completamente novedosa”, afirmó Jensen Huang, director ejecutivo de Nvidia. previsto Durante una entrevista en marzo, tal vez con cierta audacia, dijo que la mayoría de los gráficos de los videojuegos podrían ser generados por IA en tiempo real dentro de cinco a diez años.
GameNGen también se basa en trabajos previos en el campo, citados en el artículo de GameNGen, que incluyen Modelos mundiales En 2018, JuegoGAN en 2020, y el propio Google Genio en marzo. Y un grupo de investigadores universitarios entrenó un modelo de IA (llamado “DIAMANTE“) para simular videojuegos clásicos de Atari utilizando un modelo de difusión a principios de este año.
Además, la investigación en curso sobre “modelos mundiales” o “Simuladores del mundocomúnmente asociado con modelos de síntesis de video de IA como Gen-3 Alpha de Runway y Sora de OpenAI, se está inclinando hacia una dirección similar. Por ejemplo, durante el debut de Sora, OpenAI mostró videos de demostración del generador de IA simulando Minecraft.
La difusión es clave
En un artículo de investigación preimpreso titulado “Los modelos de difusión son motores de juego en tiempo real“Los autores Dani Valevski, Yaniv Leviathan, Moab Arar y Shlomi Fruchter explican cómo funciona GameNGen. Su sistema utiliza una versión modificada de Stable Diffusion 1.4, un modelo de difusión de síntesis de imágenes lanzado en 2022 que la gente usa para producir imágenes generadas por IA.
“Resulta que la respuesta a '¿puede funcionar?' CONDENAR?' es sí para los modelos de difusión”, escribió El director de investigación de Stability AI, Tanishq Mathew Abraham, que no participó en el proyecto de investigación.
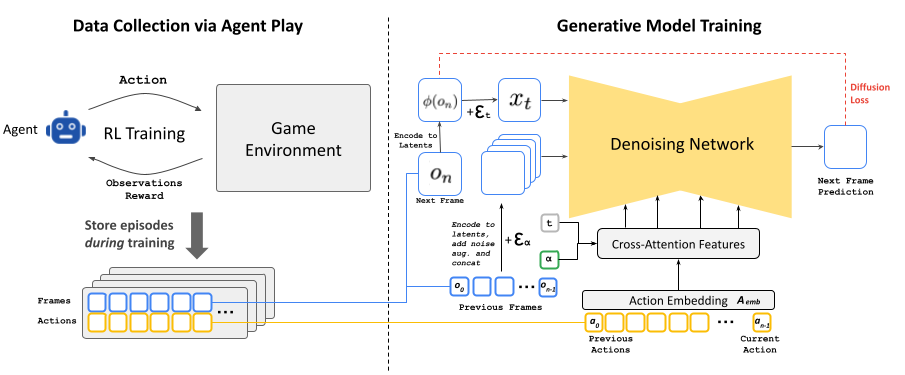
Mientras es dirigido por la entrada del jugador, el modelo de difusión predice el próximo estado del juego a partir de los anteriores después de haber sido entrenado en material extenso de Condenar en acción.
El desarrollo de GameNGen implicó un proceso de entrenamiento en dos fases. Inicialmente, los investigadores entrenaron a un agente de aprendizaje de refuerzo para que jugara Condenarcon sus sesiones de juego grabadas para crear un conjunto de datos de entrenamiento generado automáticamente (las imágenes que mencionamos). Luego usaron esos datos para entrenar el modelo de difusión estable personalizado.
Sin embargo, el uso de Stable Diffusion introduce algunos fallos gráficos, como señalan los investigadores en su resumen: “El codificador automático preentrenado de Stable Diffusion v1.4, que comprime parches de 8×8 píxeles en 4 canales latentes, genera artefactos significativos al predecir fotogramas del juego, que afectan a pequeños detalles y, en particular, al HUD de la barra inferior”.
Un ejemplo de GameNGen en acción, simulando interactivamente Doom utilizando un modelo de síntesis de imágenes.
Y ese no es el único desafío. Mantener las imágenes visualmente claras y consistentes a lo largo del tiempo (lo que a menudo se denomina “coherencia temporal” en el espacio de video de IA) puede ser un desafío. Los investigadores de GameNGen dicen que “la simulación de mundos interactivos es más que una generación de video muy rápida”, como escriben en su artículo. “El requisito de condicionar un flujo de acciones de entrada que solo está disponible durante la generación rompe algunos supuestos de las arquitecturas de modelos de difusión existentes”, incluida la generación repetida de nuevos fotogramas basados en los anteriores (lo que se denomina “autorregresión”), lo que puede conducir a la inestabilidad y a una rápida disminución de la calidad del mundo generado a lo largo del tiempo.









{kind=link}